数据来源:Latency Numbers Every Programmer Should Know
有点过时的数据:Latency numbers every programmer should know
时间单位换算: 1s = 1,000ms = 1,000,000us = 1,000,000,000ns
毫秒(ms):1s = 1,000ms
微秒(us):1ms = 1,000us
纳秒(ns):1us = 1,000ns
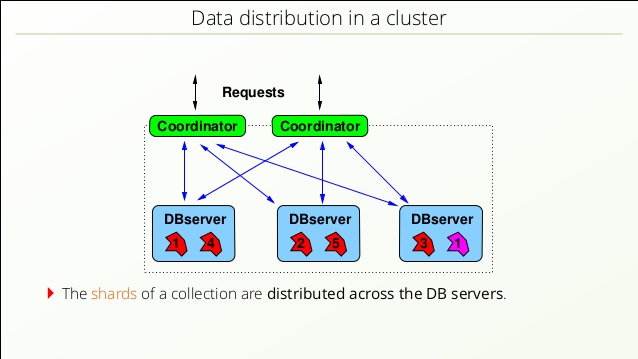
| 等待事件 | 2000 | 2005 | 2010 | 2015 | 2018 |
|---|---|---|---|---|---|
| L1缓存引用 | 6ns | 1ns | 1ns | 1ns | 1ns |
| 分支预测错误 | 19ns | 3ns | 3ns | 3ns | 3ns |
| 二级缓存引用 | 25ns | 4ns | 4ns | 4ns | 4ns |
| 互斥锁加锁/解锁 | 94ns | 17ns | 17ns | 17ns | 17ns |
| 内存引用 | 100ns | 100ns | 100ns | 100ns | 100ns |
| 压缩1KB | 11us | 2us | 2us | 2us | 2us |
| 普通网络发送2KB | 45us | 8us | 1us | 250ns | 88ns |
| SSD随机读 | 18us | 17us | 17us | 16us | 16us |
| 从内存顺序读1MB | 301us | 95us | 30us | 9us | 5us |
| 在同一个数据中心环游 | 500us | 500us | 500us | 500us | 500us |
| 从SSD顺序读1MB | 5ms | 2ms | 494us | 156us | 78us |
| 磁盘寻址 | 10ms | 7ms | 5ms | 4ms | 3ms |
| 从磁盘顺序读1MB | 20ms | 7ms | 3ms | 2ms | 1ms |
| 从CA发包到Netherlands再回来 | 150ms | 150ms | 150ms | 150ms | 150ms |